
人形机器人“网球运动员”来了 智能决策响应挑战高动态运动
网球是人形机器人面临的最具挑战性的运动之一。高速来球要求瞬间判断,全身协调决定回球质量,全场奔跑考验爆发力与控制力。当机器人真正站上球场时,能否像人类运动员一样完成判断、移动与连续回合击球成为关键。

视频中展示了机器人迅速调整站位,上下半身协同挥拍击球,并将球精准回击到指定位置。面对各种来球,它能够持续调整身体姿态与击球时机,与不同水平的对手完成多回合连续对拉。在高动态、高对抗环境中,机器人需要应对时速超过几十公里的来球、变幻莫测的落点轨迹以及对手不断变化的击球节奏。
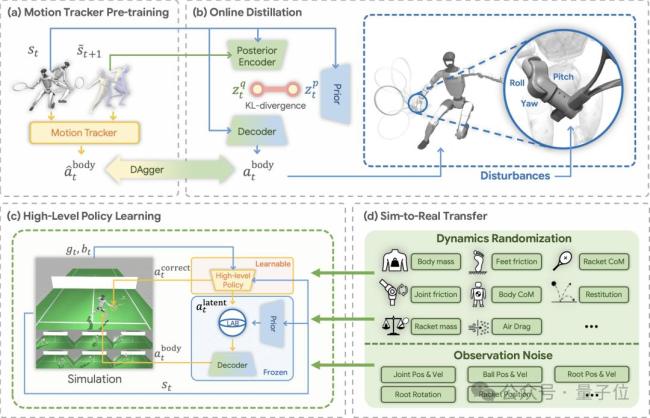
这一能力并非依赖预编程动作实现,而是通过深度强化学习自主习得。这是全球首次在人形机器人上实现高动态网球对打,标志着从“机械复刻动作”向“智能决策响应”的跨越。
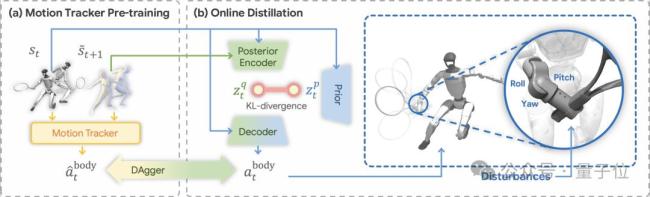
研究团队提出了一种新的机器人运动学习方法,使机器人能够从不完美的人类动作数据中学习复杂的运动技能,并在真实世界中完成高动态、高敏捷的网球击球与对打任务。传统的人形机器人运动学习依赖高质量遥操作数据进行模仿学习,但在网球这样的高动态运动场景中,这类数据几乎难以获取。而LATENT提供了一种完全不同的思路:仅靠收集前后移动、正反手挥拍、横向步伐等碎片化动作,让机器人自主学习运动技能空间,从而解锁大范围跑动急停、回击各种来球的能力。
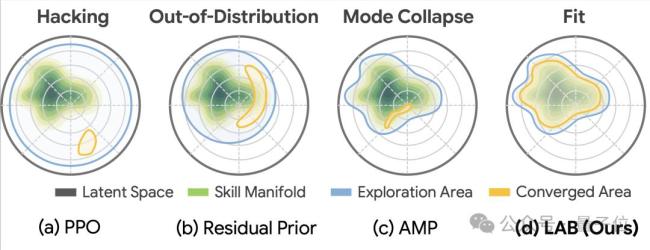
仅仅学习动作片段并不足以让机器人完成复杂运动任务,关键在于如何把这些零散经验整合成可执行的运动技能。研究团队提出在隐空间中构建一个“运动技能空间”,将碎片化的人类动作先验组织为可组合、可泛化的技能结构。通过在训练过程中对关键自由度施加随机扰动,该空间允许关键自由度上可被修正、可探索。这使机器人不再只是机械复刻训练数据,而是获得一个既保留自然运动风格、又允许击球细节被修正的技能表示。

在训练过程中,强化学习驱动的规划器会在这一技能空间中进行采样与组合。面对不同来球,机器人可以根据球速、落点以及自身姿态,对步伐、挥拍节奏和身体姿态进行实时自主规划,在保持自然运动风格的同时实现稳定击球。此外,机器人还会根据实时感知对动作进行微调,特别是在击球末端自主修正挥拍轨迹,从而控制回球方向与落点,使回击更加稳定、精准。
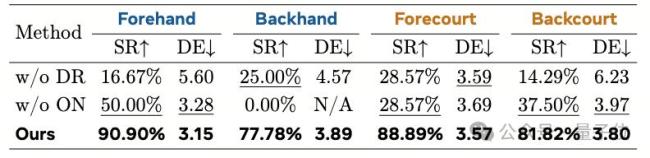
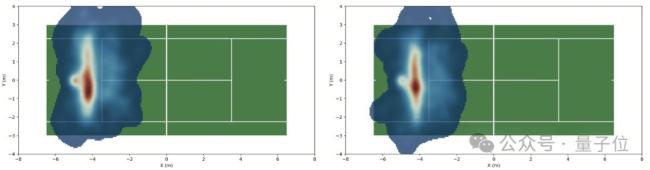
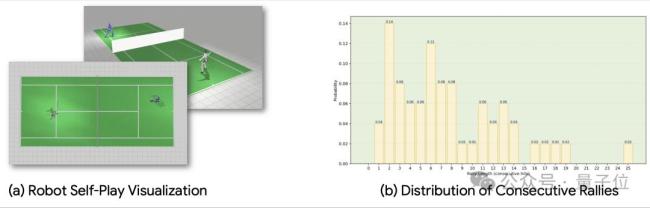
为了进一步验证LATANT的性能,研究通过将策略部署至29自由度的宇树G1机器人,并在MuJoCo仿真器和真实世界中进行大量测试。实验对比了LATANT与经典基线算法例如PPO、AMP的性能表现。结果显示,LATANT在击球成功率、回球落点精准性、关节顺滑程度与关节力矩上展现出了绝对优势。在真实物理世界中,研究者进行了连续20局的人类-机器人连续网球对拉,涵盖多种实验设置。实验证明,LATANT在不同球场位置、不同击球动作的表现下均有着较高的击球成功率和击球精准度。

除了人与机器人的对打,研究团队还展示了两个机器人之间的连续对练场景。这不禁让人联想到十年前通过自我博弈不断提升棋力、最终战胜柯洁的AlphaGo。虽然两者技术路径并不相同,但机器人之间的互动对练也为未来机器人的自主学习与持续能力进化带来了更多想象空间。
当机器人能够像人类一样移动、判断并完成复杂运动任务时,人形机器人的应用边界将进一步扩展。从运动娱乐到家庭服务,再到各种复杂的人机协作场景,具身智能正在逐渐走出实验室,进入真实世界。而LATENT所展示的正是这一趋势的重要一步。
猜你喜欢
世界纪录+1!我国科学家,重大突破
从中国科学院化学研究所获悉,该研究所朱道本院士、狄重安研究员团队联合国内合作者,成功研制出不规则多级孔结构塑料热电薄膜,其核心性能指标热电优值(zT值)突破1.64,创下柔性热电材料同温区性能世界纪录,为可穿戴设备、贴附式制冷、物联网传感器等技术发展提...
我国自主研发新一代深水多功能海洋工程船今日下水
我国自主研发的新一代深水多功能海洋工程船在江苏启东下水,全面转入调试试验阶段。本次下水的多功能海洋工程船是我国面向深海开发需求自主研发的高端海工装备,采用双层结构、单体流线型设计,总长126米、型宽28米,船舶装备400吨级近海起重机,预搭载3000吨级卷缆...
睡前加餐不长胖:选对食物,让睡眠成为减肥加速器
睡前加餐不长胖:选对食物,让睡眠成为减肥加速器很多人认为“睡前吃东西=容易胖”,但对于想减肥的人来说,睡个好觉恰恰是控制体重的重要一环。睡眠不足会导致皮质醇升高、瘦素下降,让你第二天更想吃高糖高油食物。与其饿得辗转反侧,不如选对“助眠宵夜”,既能安抚神...
节后大规模招聘会 1000家企业提供超1.3万岗位
3日,上海市举办2026年春季促进就业专项行动暨高校毕业生择业对接会。作为春节后上海市首场大规模招聘会,现场汇聚了1000家企业,提供就业岗位超过1.3万个。本次招聘会不仅设立了人工智能、集成电路、生物医药三大先导产业专区,还涵盖了专精特新、养老服务等多个特...
国家为什么要放秋假,秋假对学生和家长有什么影响,秋假放好还是不放好?
国家设立秋假主要是为了让学生在学习过程中获得适当的休息与调整,同时顺应季节变化与传统文化需求。秋季气候宜人,适合开展户外活动和社会实践,有助于缓解学生的学习压力,促进身心健康发展。此外,秋假也能与国庆假期形成衔接,方便家庭安排出行或团聚,丰富学生...

相关推荐
张仪从“嘴炮王者”到“大秦第一国相”,靠的是什么暗黑手册
都说张仪凭三寸不烂之舌搅动天下风云。但这位“大忽悠鼻祖”究竟学了什么,才能把一整个时代“骗”得团团转?答案其实很纯粹:他没读过太多别的,只凭一套秘籍,把对手的心思“算”到了骨子里。张仪从“嘴炮王者”到“大秦第一国相”,靠的竟是这本千古“暗黑操作手册”……一个靠“...
朱元璋为什么就是不传位给朱棣?
1398年,朱元璋驾崩,皇太孙朱允炆即位。四年后,他的四叔燕王朱棣起兵“靖难”,攻破南京,建文帝不知所踪。后人扼腕:如果当年朱元璋直接把皇位传给朱棣,哪还有四年内战?朱棣军事天才、政治手腕、杀伐果断,哪一样不比那个书呆子朱允炆强?朱元璋不是瞎子。他比任...
500块启动,闲鱼无货源能赚到钱吗?附多个零成本小妙招
《500块启动,闲鱼无货源能赚到钱吗?附多个零成本小妙招》很多人被“一部手机、不用囤货、月入过万”的宣传吸引,想拿500块去闲鱼试试无货源。真实结果到底怎样?我结合大量案例,给你一个不含滤镜的答案,顺便分享几个更稳妥的小本赚钱思路。一、闲鱼无货源的“冰与火...